Bonjour à tous!
dans une infrastructure virtualisée la plupart d’entre nous utilisent déjà un produit tel que Veeam backup & replication pour sauvegarder (évidemment restaurer) et répliquer les machines virtuelles.
Pour un premier article nous allons faire simple, je vais vous présenter le produit Nakivo backup & replication v5.01 fonctionnant en environnement VMware vSphere.
Vous pouvez trouver la présentation éditeur sur leur site http://nakivo.com/fr/index.htm. Le lien est sur la page française mais si vous préférez, il y a l’anglais, l’allemand, le chinois et même l’arabe!
Les options les plus intéressantes sont :
-l’optimisation WAN
-le chiffrement
-la gestion des objets Active Directory (disponible en version 5.5 beta pour le moment)
-la gestion des objets Exchange
-le flash VM boot (démarrage d’une machine virtuelle à partir d’une sauvegarde compressée)
-l’integration avec les environnements cloud Amazon EC2
Le produit peut être installé sur des systèmes Windows ou Linux, ou même déployé sous forme d’appliance virtuelle. Il sera téléchargé en suivant le lien suivant : http://nakivo.com.
Nous utiliserons l’appliance pour cette fois.
Un cluster de 3 ESXi géré par un VCSA 5.5 est utilisé comme base.
1. Déploiement de l’appliance virtuelle
Comme d’habitude, une clic avec le bouton droit de la souris sur un hyperviseur permet d’afficher le menu contextuel :
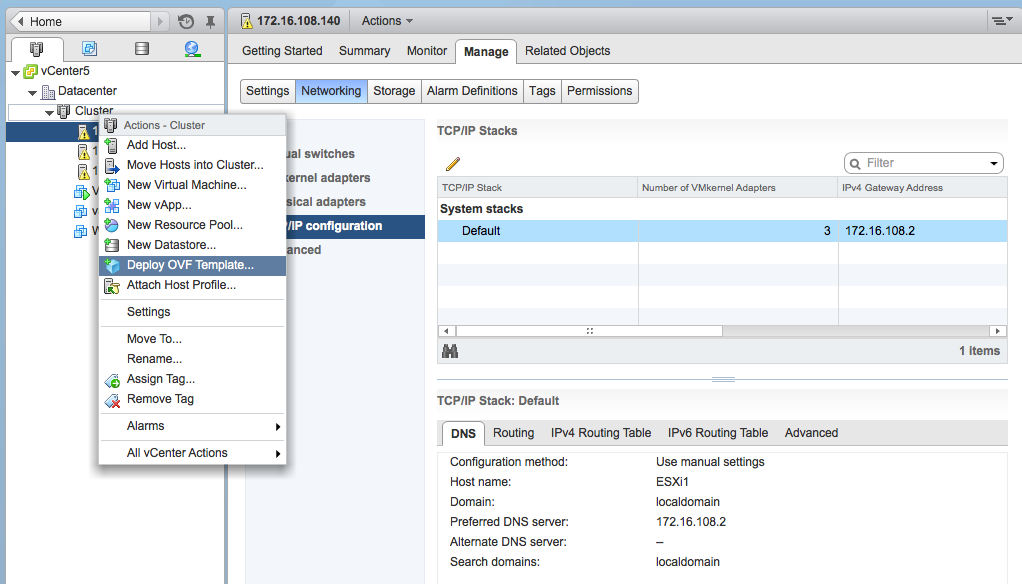
On choisit : deploy ovf template, puis on indique le chemin du fichier .ova :
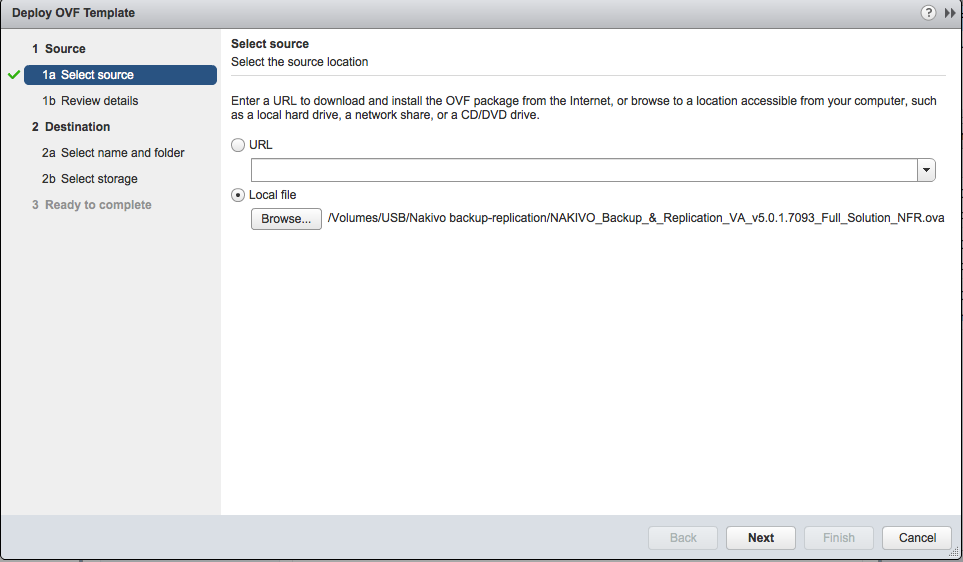
On clique sur next (suivant). Normalement le détail du produit ainsi que sa version apparaissent et sont vérifiés.
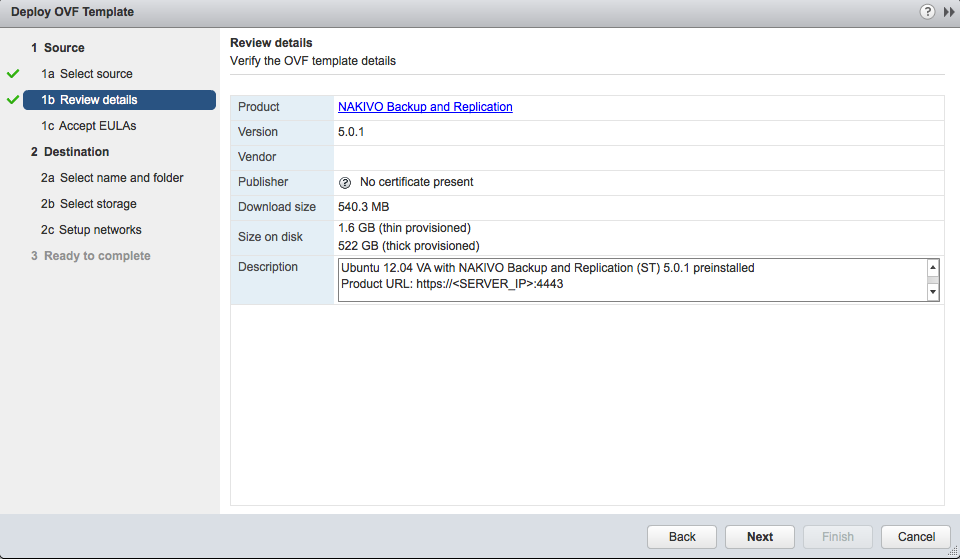
L’appliance virtuelle utilise Linux Ubuntu 12.04.
Ensuite, le fameux contrat de licence d’utilisateur final (CLUF) ou EULA pour End User License Agreement apparait et il n’est pas possible de poursuivre sans l’avoir accepté :
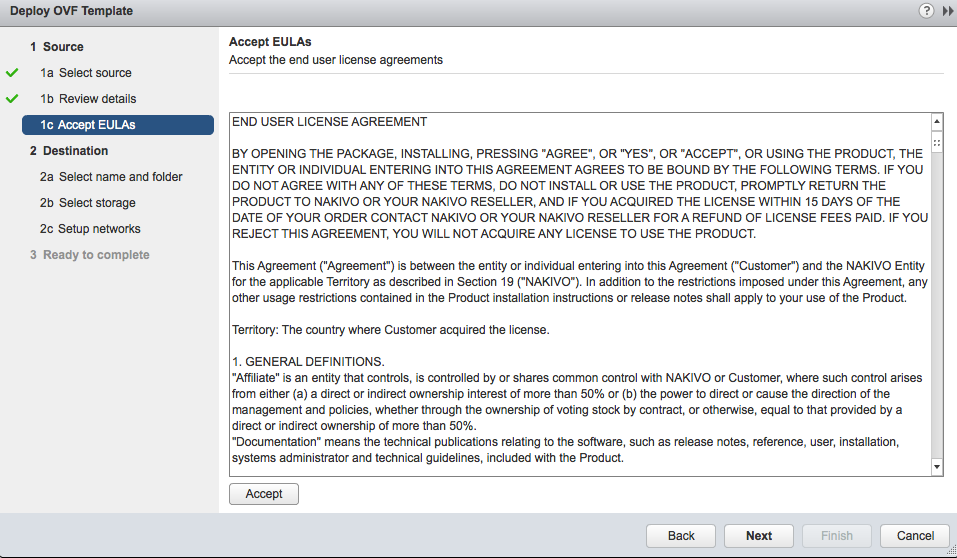
On choisit ou on déploie l’appliance (dans l’inventaire) :
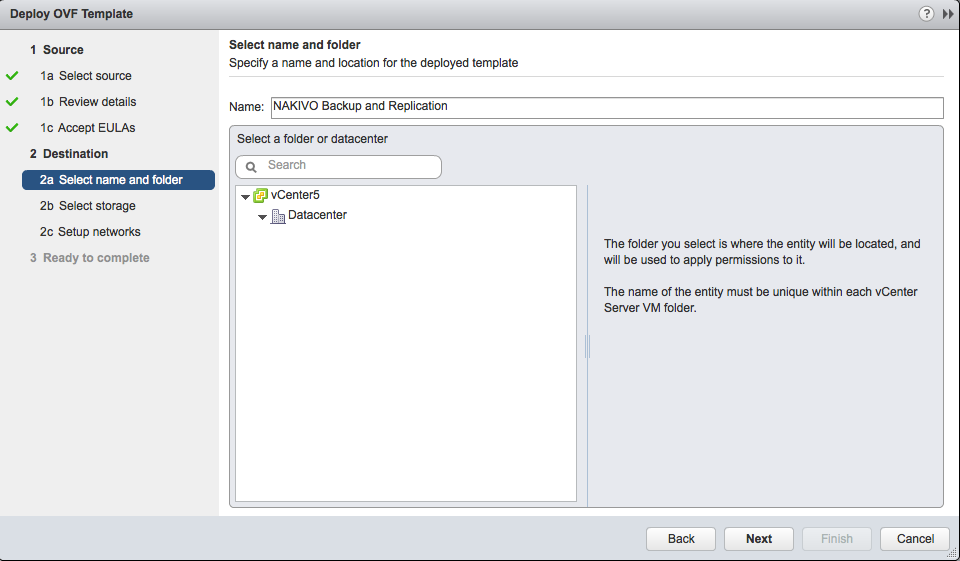
La même question se pose pour le stockage (il faut choisir le datastore ainsi que les modes thin- ou thick-provisionning) :
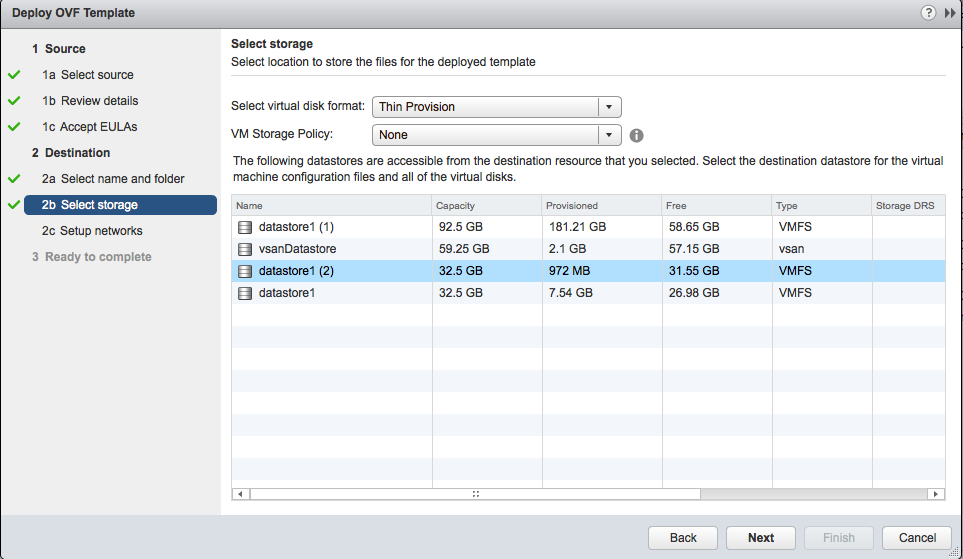
On configure ensuite la partie réseau :
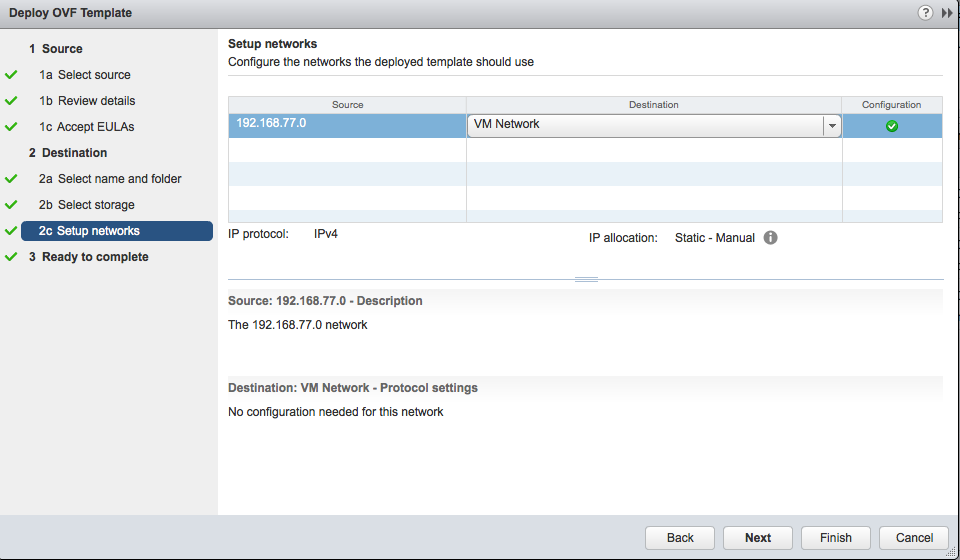
Apres confirmation des réglages (et un clic sur « finish »), le déploiement commence enfin :
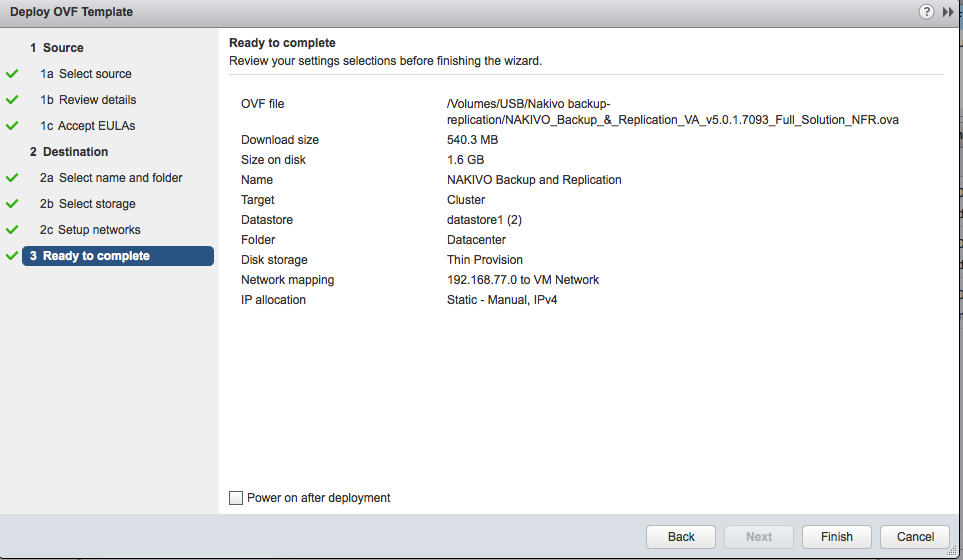
2. Connexion à l’appliance
Après le déploiement, il faut bien sur se connecter à l’appliance via l’adresse ip configurée précédemment. Nous sommes accueilli par cela :
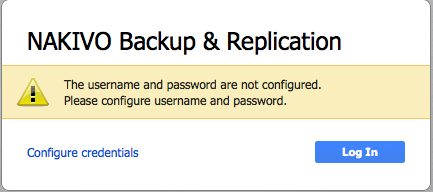
La seule action possible est de créer un identifiant pour se connecter à l’interface de gestion du produit. On clique sur « configure credentials » :
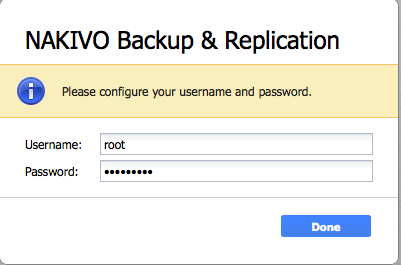
On configure un compte qu’on utilisera juste après.
3. Configuration initiale
Apres s’être connecté, on arrive sur une interface un peu vide, ce qui est normal car rien n’est encore défini (notamment ou se trouvent les machines virtuelles qu’on veut protéger via sauvegarde) :
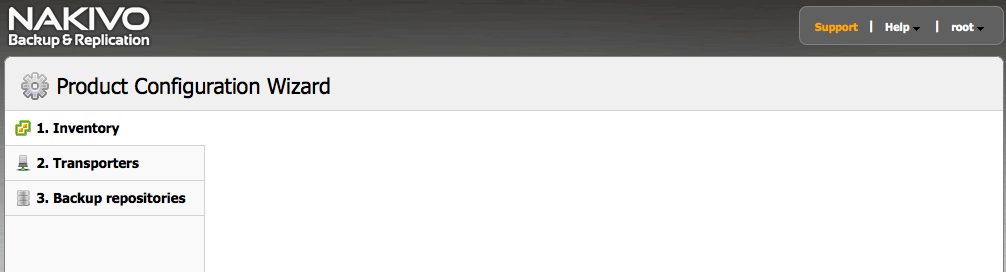
L’inventaire concerne les machines dépendant d’un serveur vCenter, les transporteurs permettent le cas échéant d’optimiser les performances et l’optimisation WAN lors des jobs de sauvegarde et réplication. Les backup repositories sont les espaces disques sur lesquels on placera les fichiers de sauvegarde.
On ajoute le serveur vCenter :

Il faut évidemment s’authentifier avec un compte d’administrateur :
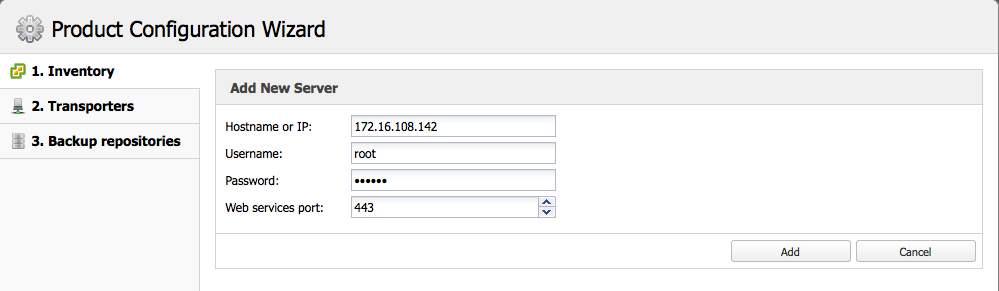
Après validation, l’inventaire apparait, tel que dans la vue « host & clusters » de vSphere :

On remarque qu’il y a obligatoirement un transporteur d’installé avec le serveur de gestion. Il sera possible d’installer d’autres transporteurs sur des machines distantes par exemple.
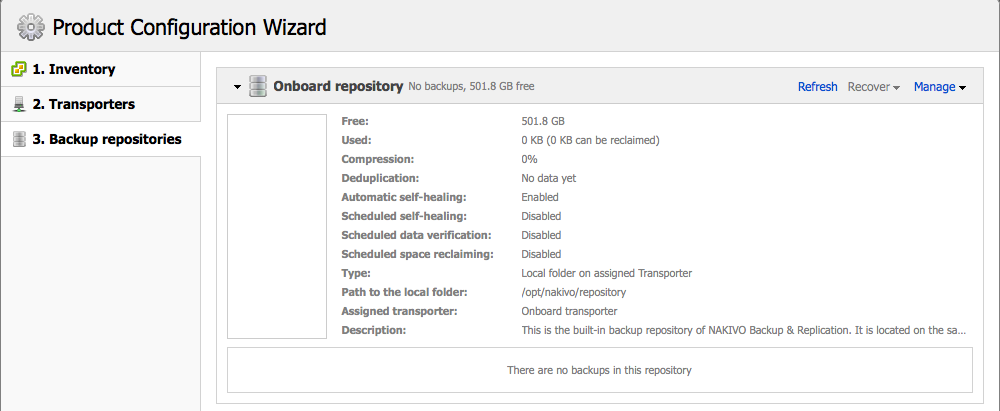
Voici les caractéristiques de l’espace de stockage réservé aux fichiers de machines virtuelles. Il est vide pour le moment. Il n’y a de plus qu’un seul espace en local. C’est une installation simple. Il est bien sur possible d’en ajouter. Notez que le produit gère la compression, la déduplication et même la récupération d’espace automatisée.
Nous sommes prêts! Il ne reste qu’à créer un job!
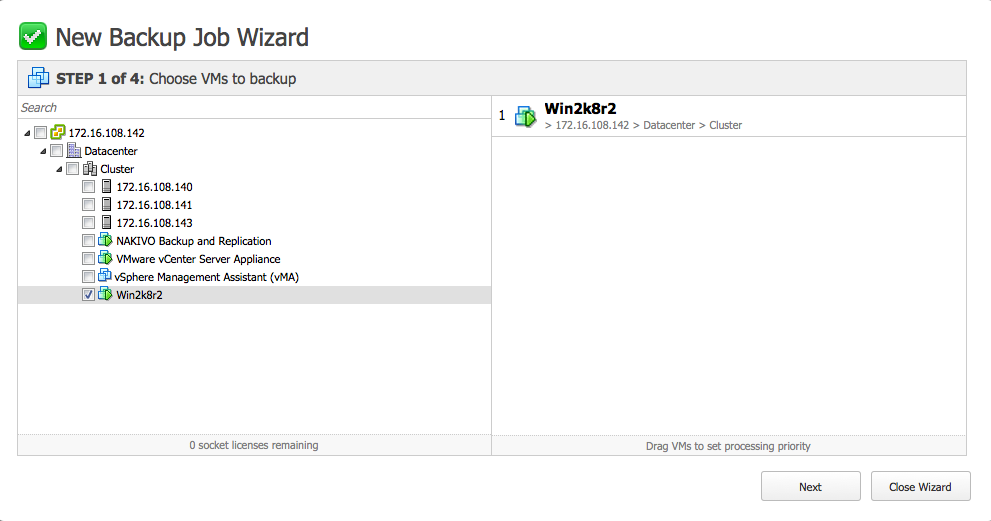
4. Création d’un job simple
Créons un job de sauvegarde (nous faisons simple, le but reste une prise en main du produit). On choisit la machine virtuelle concernée – ici Win2k8r2.
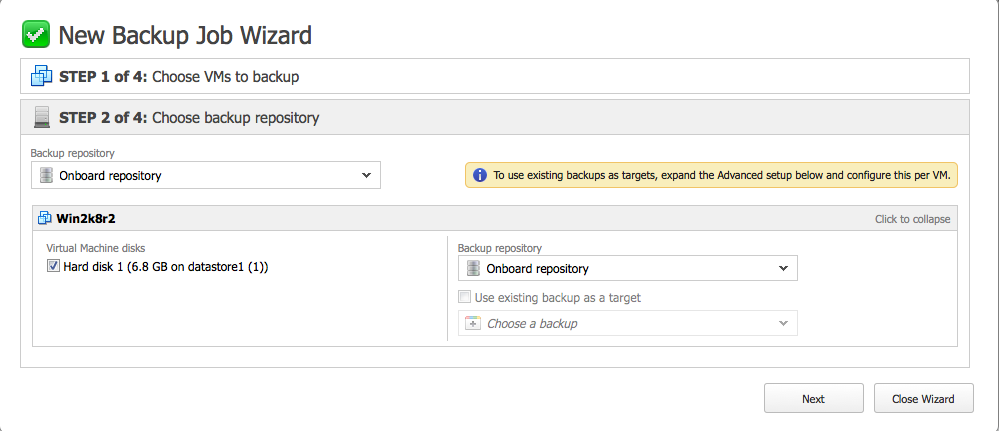
 On choisit le disque virtuel à sauvegarder ainsi que le stockage de destination (ici nous n’avons pas vraiment le choix, seul le stockage intégré est disponible, nous n’en avons pas ajouté d’autres) :
On choisit le disque virtuel à sauvegarder ainsi que le stockage de destination (ici nous n’avons pas vraiment le choix, seul le stockage intégré est disponible, nous n’en avons pas ajouté d’autres) :
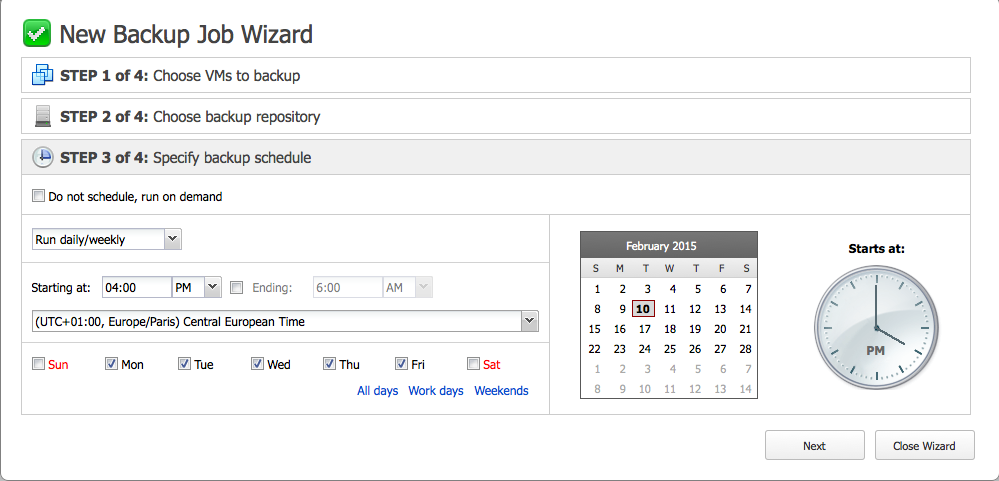
Ici, nous pouvons planifier les sauvegardes (jours, heures) ou effectuer une sauvegarde immédiate (run on demand) :
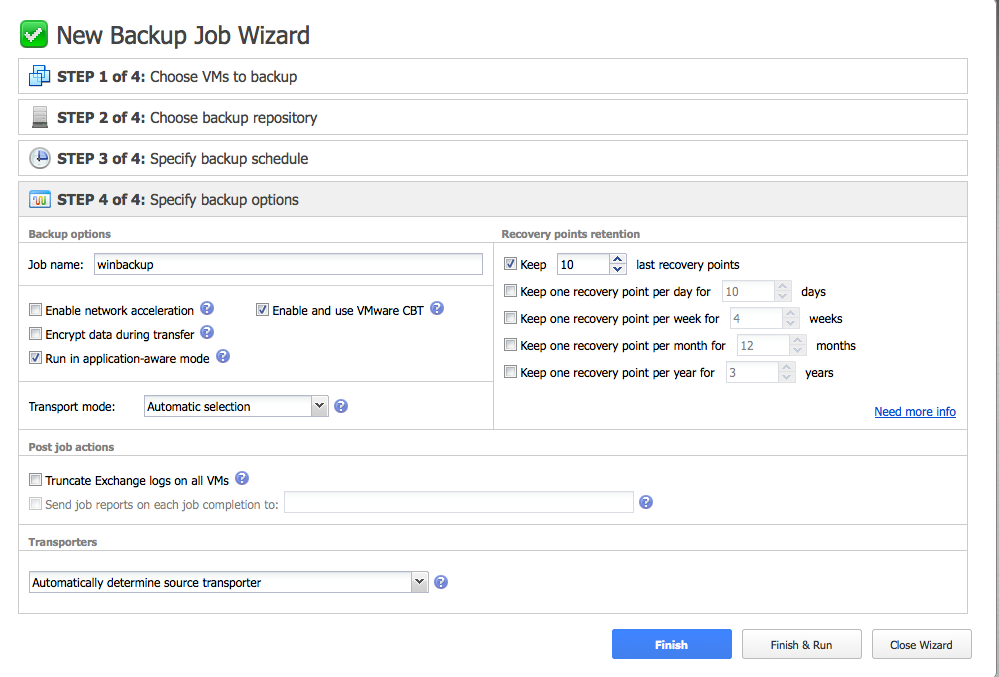
C’est ici qu’on nomme le job et qu’on choisit la politique de sauvegarde : conservation des 10 dernières sauvegardes, conserver un point de sauvegarde par semaine sur les 4 dernières semaines par exemple. On choisit aussi d’activer le change block cracking (CBT), l’optimisation WAN, le chiffrement…
Après validation, on peut vérifier que le job est bien prévu. Il se déclenchera à l’heure voulue.
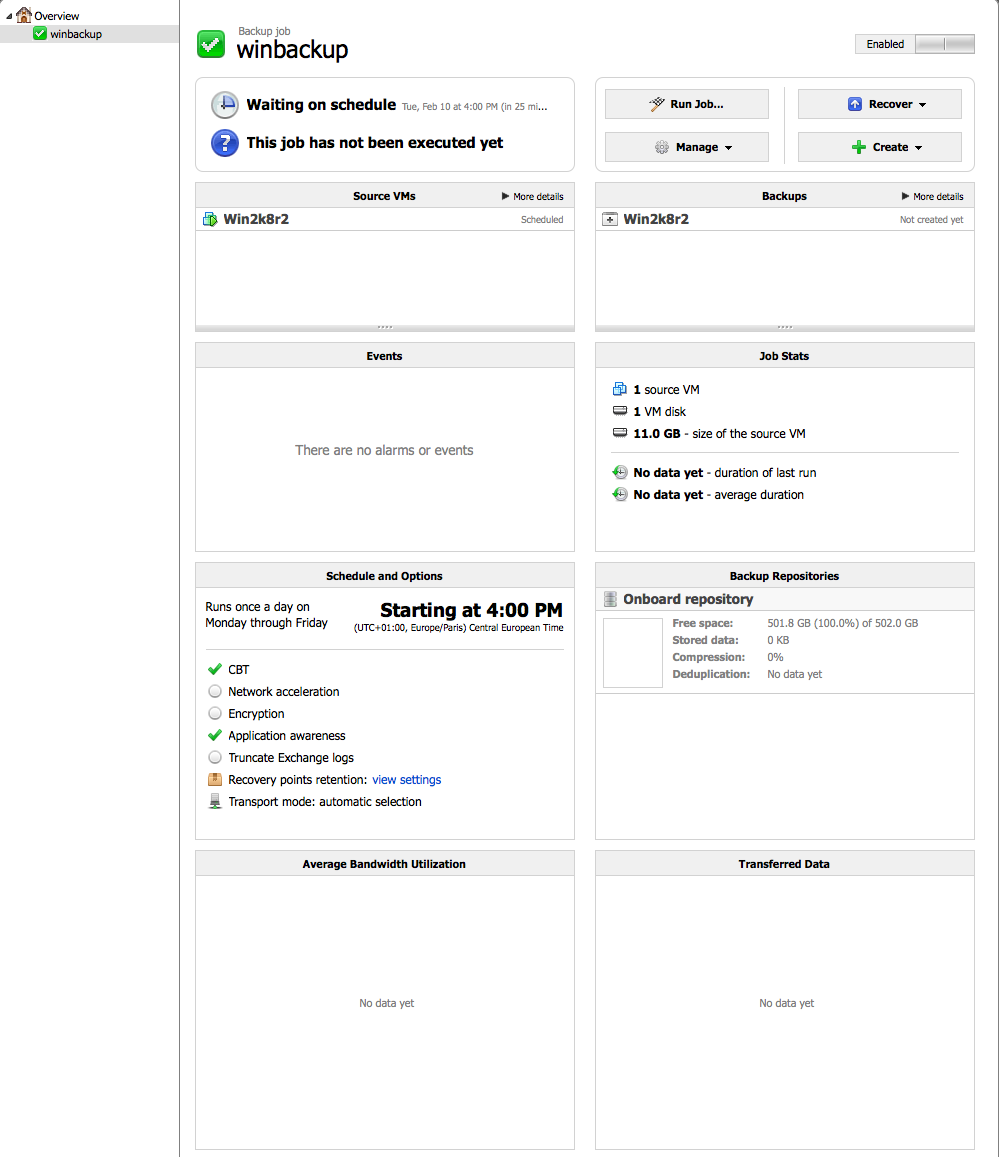
Le job commence :
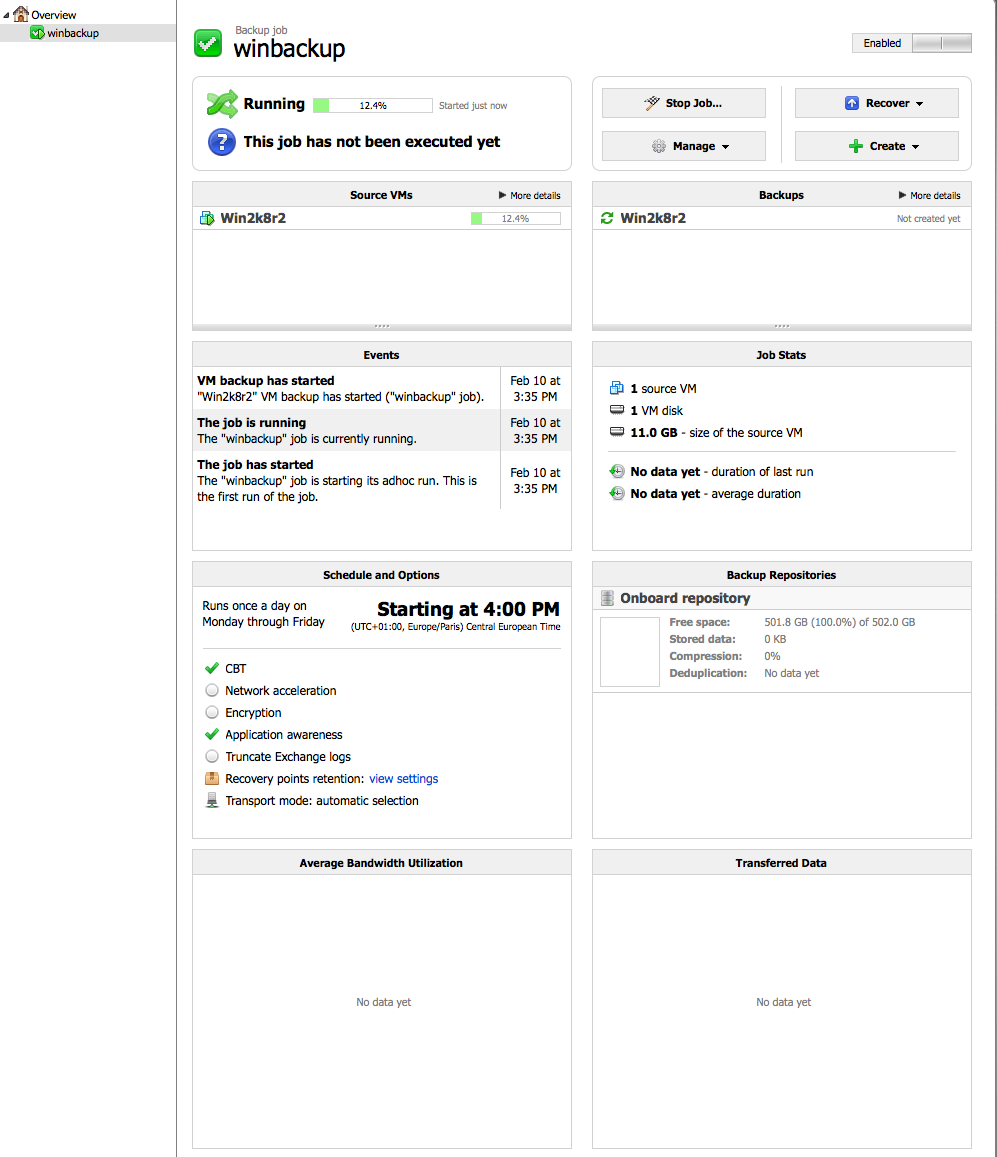
5. Ensuite 🙂
Vu la configuration (peu de charge dans l’environnement virtualisé et un job très simple) il est normal que tout se passe très bien.
J’attire votre attention sur le fait qu’en général ces produits de sauvegarde sont déployés dans les environnements de production (ce qui est normal pour pouvoir sauvegarder les applications et données de machines virtuelles critiques). Assez souvent tout se passe très bien dans les débuts mais la situation a tendance à se dégrader en fonction de l’utilisation des ressources. C’est NORMAL si des précautions ne sont pas prises. C’est pour cela qu’il existe plusieurs possibilités au niveau architecture (notamment déporter les « tranporters », et le stockage des fichiers sauvegardés afin de ne pas utiliser l’infrastructure de stockage de production).
Attention donc à bien surveiller que les sauvegardes ne perturbent pas la production car on perd ici tout l’intérêt de ces types de produits.
En espérant que cela vous sera utile,
A bientôt
Eric Fourn.
Hello, Eric! You’ve mentioned Nakivo in your article. Is it possible to add a reference to our official website? (https://www.nakivo.com/) I’ll be grateful for your answer.
Hello Vladislav! It was already mentioned but I had some formatting issues. Solved now!